System Admin Best Practices for Making and Managing Backup Operations
Recipe ID: hsts-r62
Self-paced training
We offer Linux, database design,bash scripting, Linux server management, SQL coding and more classes in self-paced video format starting at $60. Click here to learn more and register. For complete self-paced system admin training, visit our System Admin- Complete Training Bundle page.
Recipe Overview
This article explains about why, how, and when to make backups, and how to restore things from backups. Making and managing backup files and folders as well as how to recover them are required from all system admins.
1. On the importance of being backed up
Your data is valuable. It will cost you time and effort re-create it, and that costs money or at least personal grief and tears; sometimes it can't even be re-created, e.g., if it is the results of some experiments. Since it is an investment, you should protect it and take steps to avoid losing it.
There are basically four reasons why you might lose data: hardware failures, software bugs, human action, or natural disasters. Although modern hardware tends to be quite reliable, it can still break seemingly spontaneously. The most critical piece of hardware for storing data is the hard disk, which relies on tiny magnetic fields remaining intact in a world filled with electromagnetic noise. Modern software doesn't even tend to be reliable; a rock solid program is an exception, not a rule. Humans are quite unreliable, they will either make a mistake, or they will be malicious and destroy data on purpose. Nature might not be evil, but it can wreak havoc even when being good. All in all, it is a small miracle that anything works at all.
Backups are a way to protect the investment in data. By having several copies of the data, it does not matter as much if one is destroyed (the cost is only that of the restoration of the lost data from the backup).
It is important to do backups properly. Like everything else that is related to the physical world, backups will fail sooner or later. Part of doing backups well is to make sure they work; you don't want to notice that your backups didn't work. Adding insult to injury, you might have a bad crash just as you're making the backup; if you have only one backup medium, it might be destroyed as well, leaving you with the smoking ashes of hard work. Or you might notice, when trying to restore, that you forgot to back up something important, like the user database on a 15000 user site. Best of all, all your backups might be working perfectly, but the last known tape drive reading the kind of tapes you used was the one that now has a bucketful of water in it.
When it comes to backups, paranoia is in the job description.
2. Selecting the backup medium
The most important decision regarding backups is the choice of backup medium. You need to consider cost, reliability, speed, availability, and usability.
Cost is important, since you should preferably have several times more backup storage than what you need for the data. A cheap medium is usually a must.
Reliability is extremely important, since a broken backup can make a grown man cry. A backup medium must be able to hold data without corruption for years. The way you use the medium affects it reliability as a backup medium. A hard disk is typically very reliable, but as a backup medium it is not very reliable, if it is in the same computer as the disk you are backing up.
Speed is usually not very important, if backups can be done without interaction. It doesn't matter if a backup takes two hours, as long as it needs no supervision. On the other hand, if the backup can't be done when the computer would otherwise be idle, then speed is an issue.
Availability is obviously necessary, since you can't use a backup medium if it doesn't exist. Less obvious is the need for the medium to be available even in the future, and on computers other than your own. Otherwise you may not be able to restore your backups after a disaster.
Usability is a large factor in how often backups are made. The easier it is to make backups, the better. A backup medium mustn't be hard or boring to use.
The typical alternatives are floppies and tapes. Floppies are very cheap, fairly reliable, not very fast, very available, but not very usable for large amounts of data. Tapes are cheap to somewhat expensive, fairly reliable, fairly fast, quite available, and, depending on the size of the tape, quite comfortable.
There are other alternatives. They are usually not very good on availability, but if that is not a problem, they can be better in other ways. For example, magneto-optical disks can have good sides of both floppies (they're random access, making restoration of a single file quick) and tapes (contain a lot of data).
3. Selecting the backup tool
There are many tools that can be used to make backups. The traditional UNIX tools used for backups are tar, cpio, and dump. In addition, there are large number of third party packages (both freeware and commercial) that can be used. The choice of backup medium can affect the choice of tool.
tar and cpio are similar, and mostly equivalent from a backup point of view. Both are capable of storing files on tapes, and retrieving files from them. Both are capable of using almost any media, since the kernel device drivers take care of the low level device handling and the devices all tend to look alike to user level programs. Some UNIX versions of tar and cpio may have problems with unusual files (symbolic links, device files, files with very long pathnames, and so on), but the Linux versions should handle all files correctly.
dump is different in that it reads the filesystem directly and not via the filesystem. It is also written specifically for backups; tar and cpio are really for archiving files, although they work for backups as well.
Reading the filesystem directly has some advantages. It makes it possible to back files up without affecting their time stamps; for tar and cpio, you would have to mount the filesystem read-only first. Directly reading the filesystem is also more effective, if everything needs to be backed up, since it can be done with much less disk head movement. The major disadvantage is that it makes the backup program specific to one filesystem type; the Linux dump program understands the ext2 filesystem only.
dump also directly supports backup levels (which we'll be discussing below); with tar and cpio this has to be implemented with other tools.
A comparison of the third party backup tools is beyond the scope of this book. The Linux Software Map lists many of the freeware ones.
4. Simple backups
A simple backup scheme is to back up everything once, then back up everything that has been modified since the previous backup. The first backup is called a full backup, the subsequent ones are incremental backups. A full backup is often more laborious than incremental ones, since there is more data to write to the tape and a full backup might not fit onto one tape (or floppy). Restoring from incremental backups can be many times more work than from a full one. Restoration can be optimized so that you always back up everything since the previous full backup; this way, backups are a bit more work, but there should never be a need to restore more than a full backup and an incremental backup.
If you want to make backups every day and have six tapes, you could use tape 1 for the first full backup (say, on a Friday), and tapes 2 to 5 for the incremental backups (Monday through Thursday). Then you make a new full backup on tape 6 (second Friday), and start doing incremental ones with tapes 2 to 5 again. You don't want to overwrite tape 1 until you've got a new full backup, lest something happens while you're making the full backup. After you've made a full backup to tape 6, you want to keep tape 1 somewhere else, so that when your other backup tapes are destroyed in the fire, you still have at least something left. When you need to make the next full backup, you fetch tape 1 and leave tape 6 in its place.
If you have more than six tapes, you can use the extra ones for full backups. Each time you make a full backup, you use the oldest tape. This way you can have full backups from several previous weeks, which is good if you want to find an old, now deleted file, or an old version of a file.
4.1. Making backups with tar
A full backup can easily be made with tar:
# tar --create --file /dev/ftape /usr/src tar: Removing leading / from absolute path names in the archive # |
The example above uses the GNU version of tar and its long option names. The traditional version of tar only understands single character options. The GNU version can also handle backups that don't fit on one tape or floppy, and also very long paths; not all traditional versions can do these things. (Linux only uses GNU tar.)
If your backup doesn't fit on one tape, you need to use the --multi-volume (-M) option:
# tar -cMf /dev/fd0H1440 /usr/src tar: Removing leading / from absolute path names in the archive Prepare volume #2 for /dev/fd0H1440 and hit return: # |
Note that you should format the floppies before you begin the backup, or else use another window or virtual terminal and do it when tar asks for a new floppy.
After you've made a backup, you should check that it is OK, using the --compare (-d) option:
# tar --compare --verbose -f /dev/ftape usr/src/ usr/src/linux usr/src/linux-1.2.10-includes/ .... # |
Failing to check a backup means that you will not notice that your backups aren't working until after you've lost the original data.
An incremental backup can be done with tar using the --newer (-N) option:
# tar --create --newer '8 Sep 1995' --file /dev/ftape /usr/src --verbose tar: Removing leading / from absolute path names in the archive usr/src/ usr/src/linux-1.2.10-includes/ usr/src/linux-1.2.10-includes/include/ usr/src/linux-1.2.10-includes/include/linux/ usr/src/linux-1.2.10-includes/include/linux/modules/ usr/src/linux-1.2.10-includes/include/asm-generic/ usr/src/linux-1.2.10-includes/include/asm-i386/ usr/src/linux-1.2.10-includes/include/asm-mips/ usr/src/linux-1.2.10-includes/include/asm-alpha/ usr/src/linux-1.2.10-includes/include/asm-m68k/ usr/src/linux-1.2.10-includes/include/asm-sparc/ usr/src/patch-1.2.11.gz # |
Unfortunately, tar can't notice when a file's inode information has changed, for example, that its permission bits have been changed, or when its name has been changed. This can be worked around using find and comparing current filesystem state with lists of files that have been previously backed up. Scripts and programs for doing this can be found on Linux ftp sites.
4.2. Restoring files with tar
The --extract (-x) option for tar extracts files:
# tar --extract --same-permissions --verbose --file /dev/fd0H1440 usr/src/ usr/src/linux usr/src/linux-1.2.10-includes/ usr/src/linux-1.2.10-includes/include/ usr/src/linux-1.2.10-includes/include/linux/ usr/src/linux-1.2.10-includes/include/linux/hdreg.h usr/src/linux-1.2.10-includes/include/linux/kernel.h ... # |
You also extract only specific files or directories (which includes all their files and subdirectories) by naming on the command line:
# tar xpvf /dev/fd0H1440 usr/src/linux-1.2.10-includes/include/linux/hdreg.h usr/src/linux-1.2.10-includes/include/linux/hdreg.h # |
Use the --list (-t) option, if you just want to see what files are on a backup volume:
# tar --list --file /dev/fd0H1440 usr/src/ usr/src/linux usr/src/linux-1.2.10-includes/ usr/src/linux-1.2.10-includes/include/ usr/src/linux-1.2.10-includes/include/linux/ usr/src/linux-1.2.10-includes/include/linux/hdreg.h usr/src/linux-1.2.10-includes/include/linux/kernel.h ... # |
Note that tar always reads the backup volume sequentially, so for large volumes it is rather slow. It is not possible, however, to use random access database techniques when using a tape drive or some other sequential medium.
tar doesn't handle deleted files properly. If you need to restore a filesystem from a full and an incremental backup, and you have deleted a file between the two backups, it will exist again after you have done the restore. This can be a big problem, if the file has sensitive data that should no longer be available.
5. Multilevel backups
The simple backup method outlined in the previous section is often quite adequate for personal use or small sites. For more heavy duty use, multilevel backups are more appropriate.
The simple method has two backup levels: full and incremental backups. This can be generalized to any number of levels. A full backup would be level 0, and the different levels of incremental backups levels 1, 2, 3, etc. At each incremental backup level you back up everything that has changed since the previous backup at the same or a previous level.
The purpose for doing this is that it allows a longer backup history cheaply. In the example in the previous section, the backup history went back to the previous full backup. This could be extended by having more tapes, but only a week per new tape, which might be too expensive. A longer backup history is useful, since deleted or corrupted files are often not noticed for a long time. Even a version of a file that is not very up to date is better than no file at all.
With multiple levels the backup history can be extended more cheaply. For example, if we buy ten tapes, we could use tapes 1 and 2 for monthly backups (first Friday each month), tapes 3 to 6 for weekly backups (other Fridays; note that there can be five Fridays in one month, so we need four more tapes), and tapes 7 to 10 for daily backups (Monday to Thursday). With only four more tapes, we've been able to extend the backup history from two weeks (after all daily tapes have been used) to two months. It is true that we can't restore every version of each file during those two months, but what we can restore is often good enough.
Firgure 1 show which backup level is used each day, and which backups can be restored from at the end of the month.
Figure 1. A sample multilevel backup schedule.
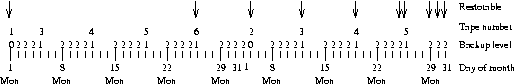
Backup levels can also be used to keep filesystem restoration time to a minimum. If you have many incremental backups with monotonously growing level numbers, you need to restore all of them if you need to rebuild the whole filesystem. Instead you can use level numbers that aren't monotonous, and keep down the number of backups to restore.
To minimize the number of tapes needed to restore, you could use a smaller level for each incremental tape. However, then the time to make the backups increases (each backup copies everything since the previous full backup). A better scheme is suggested by the dump manual page and described by the table XX (efficient-backup-levels). Use the following succession of backup levels: 3, 2, 5, 4, 7, 6, 9, 8, 9, etc. This keeps both the backup and restore times low. The most you have to backup is two day's worth of work. The number of tapes for a restore depends on how long you keep between full backups, but it is less than in the simple schemes.
Table 1. Efficient backup scheme using many backup levels
Tape |
Level |
Backup (days) |
Restore tapes |
1 |
0 |
n/a |
1 |
2 |
3 |
1 |
1, 2 |
3 |
2 |
2 |
1, 3 |
4 |
5 |
1 |
1, 2, 4 |
5 |
4 |
2 |
1, 2, 5 |
6 |
7 |
1 |
1, 2, 5, 6 |
7 |
6 |
2 |
1, 2, 5, 7 |
8 |
9 |
1 |
1, 2, 5, 7, 8 |
9 |
8 |
2 |
1, 2, 5, 7, 9 |
10 |
9 |
1 |
1, 2, 5, 7, 9, 10 |
11 |
9 |
1 |
1, 2, 5, 7, 9, 10, 11 |
... |
9 |
1 |
1, 2, 5, 7, 9, 10, 11, ... |
A fancy scheme can reduce the amount of labor needed, but it does mean there are more things to keep track of. You must decide if it is worth it.
dump has built-in support for backup levels. For tar and cpio it must be implemented with shell scripts.
6. What to back up
You want to back up as much as possible. The major exception is software that can be easily reinstalled, but even they may have configuration files that it is important to back up, lest you need to do all the work to configure them all over again. Another major exception is the /proc filesystem; since that only contains data that the kernel always generates automatically, it is never a good idea to back it up. Especially the /proc/kcore file is unnecessary, since it is just an image of your current physical memory; it's pretty large as well.
Gray areas include the news spool, log files, and many other things in /var. You must decide what you consider important.
The obvious things to back up are user files (/home) and system configuration files (/etc, but possibly other things scattered all over the filesystem).
7. Compressed backups
Backups take a lot of space, which can cost quite a lot of money. To reduce the space needed, the backups can be compressed. There are several ways of doing this. Some programs have support for for compression built in; for example, the --gzip (-z) option for GNU tar pipes the whole backup through the gzip compression program, before writing it to the backup medium.
Unfortunately, compressed backups can cause trouble. Due to the nature of how compression works, if a single bit is wrong, all the rest of the compressed data will be unusable. Some backup programs have some built in error correction, but no method can handle a large number of errors. This means that if the backup is compressed the way GNU tar does it, with the whole output compressed as a unit, a single error makes all the rest of the backup lost. Backups must be reliable, and this method of compression is not a good idea.
An alternative way is to compress each file separately. This still means that the one file is lost, but all other files are unharmed. The lost file would have been corrupted anyway, so this situation is not much worse than not using compression at all. The afio program (a variant of cpio) can do this.
Compression takes some time, which may make the backup program unable to write data fast enough for a tape drive. This can be avoided by buffering the output (either internally, if the backup program if smart enough, or by using another program), but even that might not work well enough. This should only be a problem on slow computers.
Additional Linux Resources
Here is a list of resources for learning Linux:Resources for System Administrators
- Linux System Admin Guide- What is Linux Operating System and how it works
- Linux System Admin Guide- What are Directory Tree and Filesystem Hierarchy in Linux
- Linux System Admin Guide- Introduction to Linux File Systems for System Admins
- Linux System Admin Guide- Overview of Linux Virtual Memory and Disk Buffer Cache
- Linux System Admin Guide- Best Practices for Monitoring Linux Systems
- Linux System Admin Guide- Best Practices for Performing Linux Boots and Shutdowns
- Linux System Admin Guide- Best Practices for Making and Managing Backup Operations
Resources for Linux Kernel Programmers
- How Linux Operating System Memory Management works
- Comprehensive Review of Linux Kernel Operating System Processes
- Comprehensive Review of Linux File System Architecture and Management
- What are mechanisms behind Linux Kernel task management
- How Linux Kernel Sources and Functions work
- Comprehensive look at how Linux Data Structures work
Linux File System Dictionary
Comprehensive Review of How Linux File and Directory System Works
Hands-on Linux classes
- Introduction to Linux and Shell programming
- Linux System Administration
- Korn Shell and Bash Shell Coding
Linux Operating System Distributions
- Comprehensive list of all Linux OS distributions
- Comprehensive list of all special purpose Linux distributions
- Comprehensive list of all secure Linux distributions for cybersecurity professionals
Private and Custom Coding Classes
We offer private coding classes for beginners online and offline (at our Virginia site) with custom curriculum for most of our classes for $59 per hour online or $95 per hour in virginia. Give us a call or submit our Private Coding Classes for Beginners form to discuss your needs.